
Developing a parameter weightage-based feed


5 min read

We recently deployed a new discussion feed on hashnode, which comes close to matching our requirements. In this article, we'll discuss how we created it.

Before we get into it, just a heads-up that features like feed are developed with many hits and trials. We set a target to achieve a particular requirement, but there's no one sure-shot way to achieve it. It takes a lot of iterations to reach a stage that comes close to ticking our requirements.
Requirements
Now, let's state the requirements for our discussion feed:
Filters
Consider posts created within the last year
These posts should have at least:
💬 1 comment (It is a discussion feed, after all :P)
👀 10 views
👍 10 reactions
Weightage
Number of comments on a post
10, the posts with a high number of comments should be given more preferenceThe recency of the latest comment
20, the posts with recent comment activity should surface at the top
Constructing the Feed
We can divide the feed construction into two subcategories first is filters and the next is weightages
Filters
Filters are simple DB query filters that might look like this with the requirements:
const DISCUSSION_REACTION_THRESHOLD = 10;
const DISCUSSION_VIEW_THRESHOLD = 10;
const SINCE_DATE = dayjs().subtract(1, 'year').toDate();
const posts = await PostModel.find(
{
totalReactions: { $gte: DISCUSSION_REACTION_THRESHOLD },
dateAdded: { $gte: SINCE_DATE },
views: { $gte: DISCUSSION_VIEW_THRESHOLD }
},
);
Weightages
For the final score, let's call it discussionScore, we need to come up with an algo that takes the above-mentioned weigtages into account and sum them up. Here's what it might look like:
$$discussionScore = recencyScore + commentCountScore$$
Let's see how we can calculate the score for each of those weightages:
Comment Count Score
The absolute numbers, such as comment count could be huge numbers, we need to scale the number down to a more manageable quantity. That's why we'll use Log to the base 10 to scale the
commentCountof posts.We also need to have a denominator to measure and assign a proper weight score for each post. That denominator will be the maximum comment count that a post has received on our platform.
const NUM_COMMENTS_WEIGHT = 10; const MAX_COMMENT = Math.log10(800) // Maximum comment a post has received const commentCount = Math.log10( Math.max(post.commentCount || 0, 1) ); const commentCountScore = (commentCount / MAX_COMMENT) * NUM_COMMENTS_WEIGHT;Recency Score
Getting
recencyScoreis similar to how we calculate it for personalized feeds. We choose a time window inside which posts are eligible to get a recency score and then assign appropriate points for those posts. The most recent post will get the maximum points, ie20const DISCUSSIONS_RECENCY_WEIGHT = 20; function getRecencyScoreForDiscussions(date: Date) { // 30 days times 24 hours a day const recentTimeFrame = 30 * 24; const pointsPerHour = DISCUSSIONS_RECENCY_WEIGHT / recentTimeFrame; const difference = dayjs().diff(dayjs(date), 'hours'); const weight = Math.max(recentTimeFrame - difference, 0); return weight * pointsPerHour; }
Architecture
Now that we know how to calculate both the weightage scores required to calculate the final discussionScore. The next questions are
When should we calculate these scores?
How can we store these scores so that the feed has a low response time without causing spikes on DB?
At hashnode, we rely heavily on asynchronous event-driven architecture, so whenever a comment is added or deleted, responsePublished and responseEdited events are emitted. We listen to these events and recalculate commentCountScore for that particular post, and save it as post data with the following fields:
commentMetadata: types.object({
commentCount: types.number(),
lastCommentAddedDate: types.date(),
commentCountScore: types.number()
})
We also save other metadata in case we need to recalculate the score with a different algo later.
That was for commentCountScore , figuring out how and when to calculate recencyScore was a little tricky. Since we need to calculate recencyScore for each post when the request for the feed is made, it has to be calculated on the fly otherwise, storing the score in DB will make it stale. To overcome this, we get 1000 posts sorted by their commentCountScore when the request is made and just get the required fields to calculate the final discussionScore. This is what the DB query might look like
const posts = await PostModel.find(
{
totalReactions: { $gte: DISCUSSION_REACTION_THRESHOLD },
dateAdded: { $gte: SINCE_DATE },
views: { $gte: DISCUSSION_VIEW_THRESHOLD }
},
{
sort: {
"commentMetadata.commentCountScore": -1
},
projection: {
_id: 1,
commentMetadata: 1,
dateAdded: 1
},
limit: 1000
}
);
These 1000 postIds are then sorted on the fly by their final discussionScore, and the requested page's posts are sent back to DB to get the full-fledged posts with all the details. Then, those posts are sent back to the client.
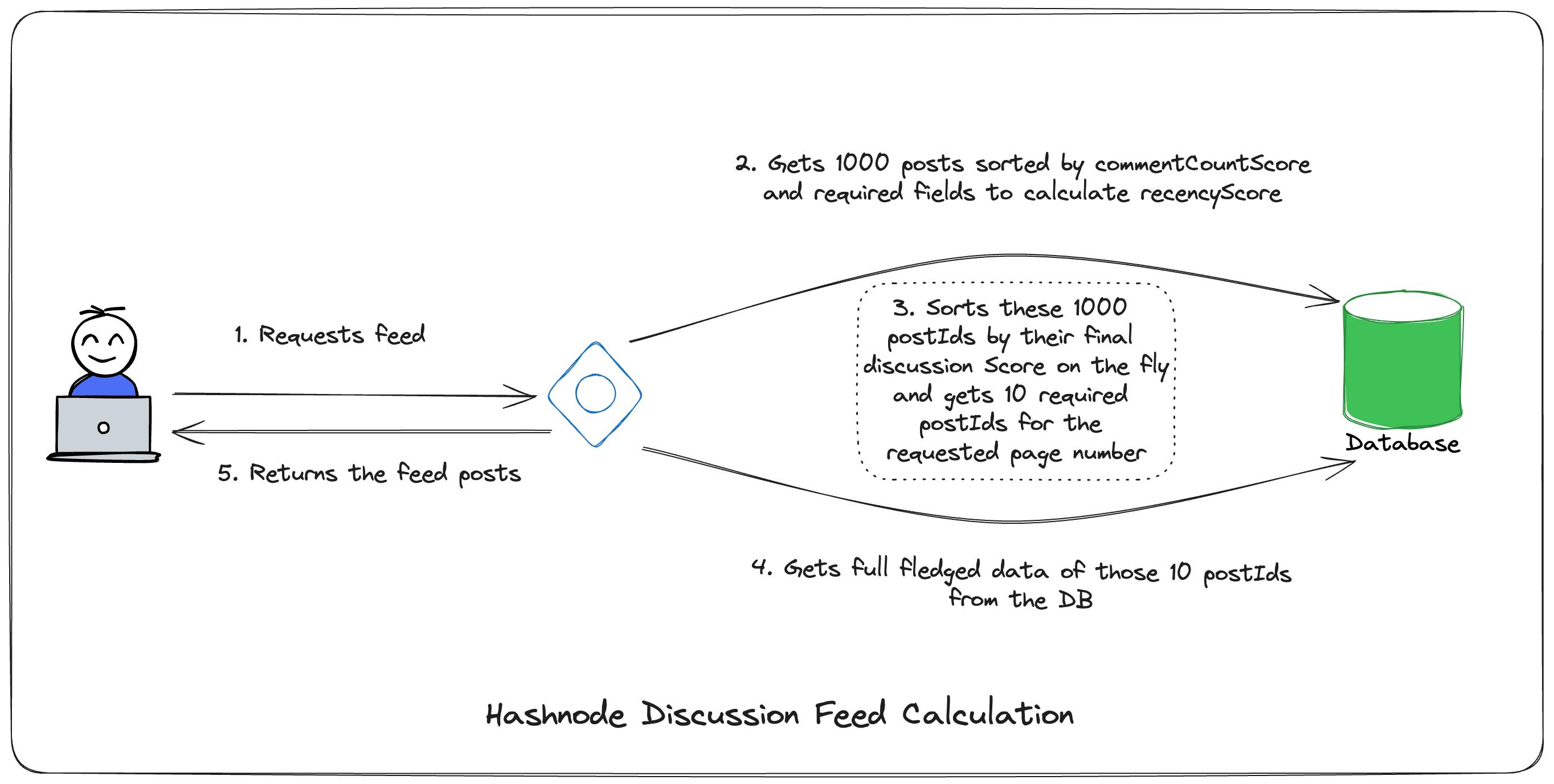
To make it fast and avoid overloading the DB, we store these postIds in Redis and extensively use the Stellate cache. Also, indexing the required fields like commentCountScore makes the DB query run faster.
Conclusion
In this article, we discuss the process of creating a discussion feed on Hashnode with specific requirements such as filters and weightages. We dive into the architecture of constructing the feed, calculating scores for comment count and recency, and optimizing the process using an asynchronous event-driven architecture. By leveraging Redis and Stellate cache, we ensure a fast and efficient feed without overloading the database.
Shoutout to Florian Fuchs for brainstorming with me and special mention to the personalized feed from which we drew a lot of inspiration. Please feel free to share your thoughts in the comments.
Cheers ✌️
Comments (2)


Great work. Love the development progress going on here. Thanks for everything you do!